

The last couple of weeks I am back on my MRes lab skills teaching. Each year I add a little bit to the program based on common issues that come up during the year. Multiple comparison testing, or more accurately, failing to account for multiple comparisons, is an area where many students, postdocs and even faculty have problems so I have been trying different things to get the message across.
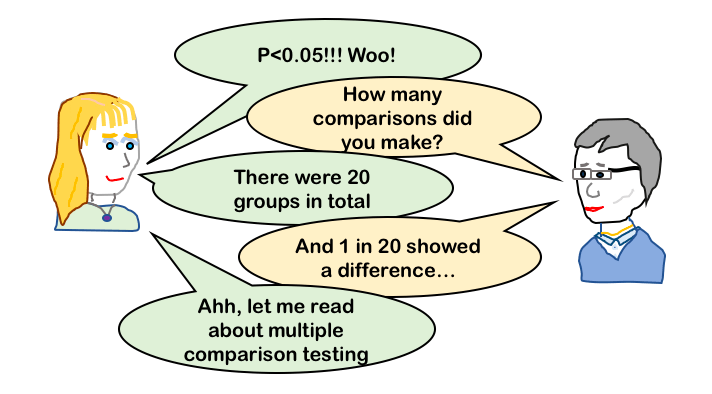
From an overly simplified standpoint*, if you are comparing two groups using a T test and get a P value of 0.05 this means that there is a 5% chance that the difference you have observed occurred by chance i.e. is a false positive. In other words, you can be 95% confident that the difference is real. However, if you had three groups and took the same approach there would be twice as many opportunities for a false positive. To account for this we use a different test t; in this example, usually an ANOVA.
That’s all fine and most people absorb this pretty readily. However, multiple comparisons are also relevant when you are measuring many different things in the same samples. If you have two groups (e.g. drug treated and untreated) and measure the expression of 50 genes and do a T test for each of the genes you will get 50 different P values. Each of those P values are an indication that the specific result could have occurred by chance. But, the more comparisons you make the higher the probability that some of them will be false positives and therefore your overall confidence in any one finding decreases.
It’s like your are playing roulette with a chip on a single number. Spin the wheel once and there is a 1/37 chance your number comes up, spin the wheel 50 times and it’s more likely that one of those spins will give your number (you’d be surprised and disappointed if it didn’t!).
There are statistical solutions for multiple outcome variables too (e.g. a MANOVA is an ANOVA designed for multiple outcome variables). So, remember to think about whether you have multiple comparisons when choosing your stats test.
The practical upshot of increasing the number of comparisons in your experiment is that you will need more samples to obtain the same statistical power. Or saying it the other way, you will be less confident in the results you get from the same number of experiments. In practical terms this has implications in sample availability, ethical cost, time cost and processing costs. This is one (of many) reasons why good experimental design is key.
Interested in experimental design? I put some of my lectures on this site recently.
independence and assigning groups
*lots of assumptions here including normally distributed data. These caveats are important but I want the core concept to be absorbed, hence the over-simplification!
